

Les systèmes d’Intelligence Artificielle (IA) n’automatisent plus uniquement les tâches répétitives : ils peuvent désormais traiter certaines formes d’incertitude – encadrées -, autrefois réservées au jugement humain. Seront d’abord menacées les professions à composante principalement intellectuelle – par exemple les traducteurs, les juristes, les économistes, etc. -, mais aussi, à terme, des professions manuelles complexes.
Pour se préparer à ce bouleversement du marché du travail, nous avons besoin d’outils prospectifs pour anticiper l’impact à venir : quels métiers sont menacés en priorité ? Dans quels secteurs ? Quels territoires sont les plus vulnérables ? Quels métiers émergeront ?
Pour répondre à ces questions, une approche fine consiste à analyser les tâches associées à chaque emploi afin d’évaluer leur propension à être automatisées. A l’échelle d’une économie dans son ensemble, l’approche par tâche constitue aujourd’hui l’outil le plus robuste pour cartographier, métier par métier, l’exposition à l’automatisation, grâce à des bases de données telles que O*NET.
L’Observatoire des Emplois Menacés et Émergents propose une analyse prospective, transparente et modulable, de la propension d’automatisation des tâches de chaque métier. Elle repose sur :
– Une extraction linguistique avancée : chaque tâche est analysée à l’échelle des actions élémentaires (verbe – objet – modificateur), avec un traitement des erreurs de balisage syntaxique (ex : verbes ambigus mal étiquetés, participes adjectivaux filtrés) et un enrichissement des structures extraites par la propagation contextuelle des relations grammaticales.
– Un système de notation (scoring) modulaire et paramétrable : toutes les règles d’évaluation (nature de l’action, type d’objet manipulé, complexité cognitive, modalités de communication, etc.) sont définies dans un fichier de configuration externe (YAML), entièrement ajustable sans modification du code Python. Cette construction garantit une adaptation rapide aux progrès technologiques et permet de simuler différents scénarios d’automatisation, de manière transparente et traçable.
Fondée sur la base de données O*NET (environ 1000 métiers décrits par tâches), notre approche explore différents scénarios d’automatisation : LLM utilisés de façon isolée, agents autonomes, workflows automatisés, IA Générale, et robotique humanoïde assistée par IA Générale. Les deux derniers sont les plus incertains car l’IA générale n’a pas encore émergé. Les trois premiers correspondent à des technologies en développement mais déjà existantes, les LLMs.
Des notes d’automatisation sont attribuées à chaque composante linguistique du texte décrivant la tâche (verbe, COD, conjonction). Par exemple le verbe “calculer” recevra un score élevé pour les LLM mais le couple verbe et COD “calculer, dimension” recevra un score plus bas car il peut indiquer une nécessité de prise de mesure physique. La fragmentation de la tâche en éléments syntaxiques permet ainsi d’affiner la notation.
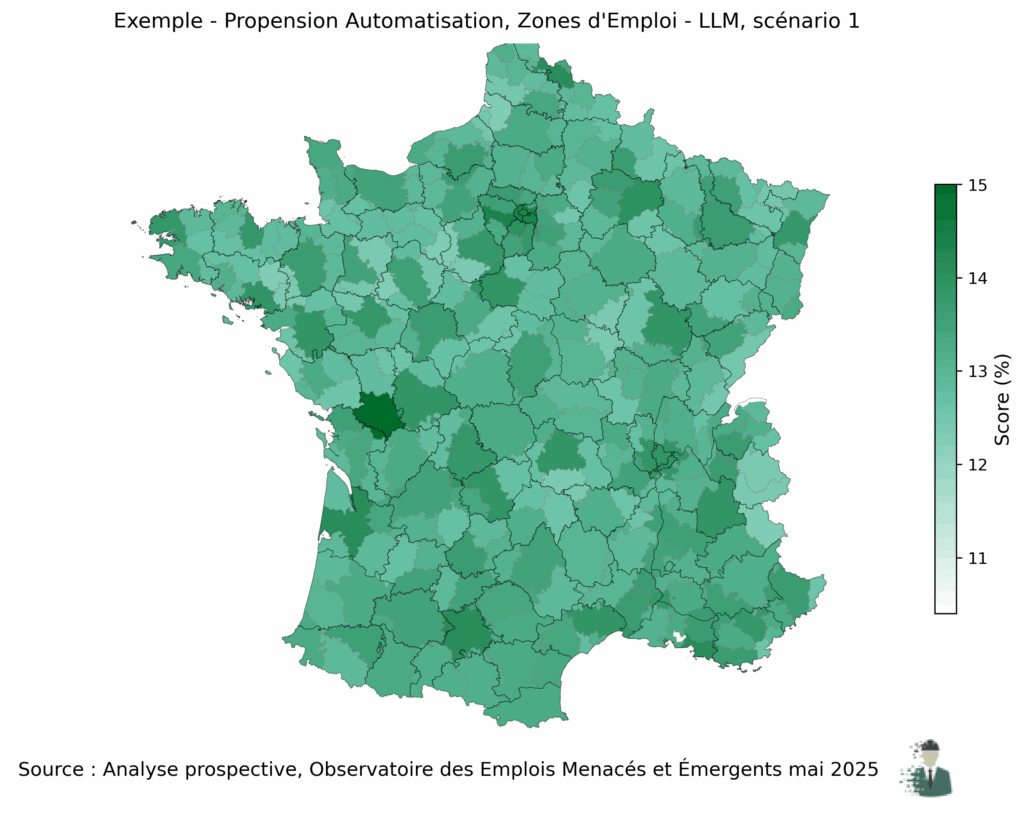
🔹 Exemple de résultat : exposition territoriale à l’automatisation (scénario LLM isolés)
La méthode présentée ici permet donc d’attribuer un score d’automatisation à chaque tâche décrite dans les bases de données métiers. En agrégeant ces scores par métier, puis par zone d’emploi (avec pondération par effectifs), on peut estimer la vulnérabilité relative des territoires face à différents scénarios d’automatisation par IA.
La carte ci-dessous illustre un exemple de sortie du pipeline pour le scénario LLM (modèles de langage), utilisés isolément. Elle présente une première estimation de l’exposition territoriale aux LLM, obtenue à partir d’un paramétrage initial (version v1.0 des règles de notation YAML). Ce paramétrage est conçu pour évoluer afin d’intégrer les progrès technologiques et les perfectionnements méthodologiques continus. L’objectif est de fournir une méthodologie robuste, reproductible et adaptable aux évolutions futures, plutôt qu’un instantané figé.
Cette illustration ne prend en compte que l’impact direct des LLMs utilisés de manière isolée, c’est-à-dire sans prise en compte de leur intégration dans des agents IA autonomes ou des workflows automatisés complexes.
Quelques travaux existants
Plusieurs travaux majeurs, inspirés par les travaux pionniers de Autor, Levy, Murnane (2003) sur l’introduction des ordinateurs, ont évalué l’exposition des emplois à l’IA, entre autres :
– Brynjolfsson, Mitchell et Rock (2018) ont évalué la “suitability for machine learning” (SML) des tâches O*NET en appliquant une grille d’analyse à 18 156 tâches, basée sur des critères tels que la standardisation, la routinisation et la prévisibilité. Cette évaluation a été réalisée par des experts humains, permettant de mesurer la propension des tâches à être automatisées par l’apprentissage automatique.
– Berg et al. (2025) construisent un indice d’exposition à l’IA générative (Organisation Internationale du Travail, OIT).
– Felten, Raj et Seamans (2021) ont construit un “AI Occupational Exposure Index” en évaluant l’adéquation entre les capacités actuelles de l’IA et les compétences professionnelles décrites dans O*NET, en s’appuyant sur des jugements humains structurés, sans recourir à l’analyse textuelle automatisée des descriptions de tâches ni à une évaluation au niveau des actions élémentaires.
– Webb (2019) a mesuré l’exposition à l’IA en croisant le contenu textuel des descriptions de tâches O*NET avec celui des brevets technologiques en IA, évaluant ainsi l’alignement sémantique entre innovations et activités professionnelles à l’aide de techniques classiques de traitement du langage naturel.
– Eloundou, Manning, Mishkin et Rock (2023) ont directement interrogé un modèle de langage (GPT-4) pour évaluer, tâche par tâche dans O*NET, la propension des activités professionnelles à être impactées par les modèles de langage avancés, en construisant un “GPT exposure score” fondé sur des jugements d’aptitude du modèle lui-même.
– Noy et Zhang (2023) ont étudié expérimentalement comment l’accès à des outils d’IA générative (type ChatGPT) affecte la productivité sur certaines catégories de travail cognitif.
– Le Fonds Monétaire International (2024) a élaboré un AI Exposure Index en cartographiant manuellement et semi-automatiquement les correspondances entre capacités technologiques de l’IA générative et compétences professionnelles issues d’O*NET et d’ESCO, sans recourir à l’analyse textuelle automatisée ni à l’évaluation au niveau des actions élémentaires, aboutissant à une catégorisation des tâches en “exposed“, “automatable” ou “non-exposed“.
– Loaiza et Rigobon (2024) ont proposé un changement de paradigme avec l’indice EPOCH, qui mesure non seulement le risque d’automatisation, mais aussi le potentiel d’augmentation du travail humain par l’IA. Leur méthode repose sur une taxonomie des capacités humaines difficilement substituables (empathie, jugement, créativité, etc.), évaluées via des embeddings sémantiques, paraphrasés 20 fois par ChatGPT. Ils introduisent également une structure de complémentarité des tâches en réseau, permettant d’estimer dans quelle mesure certaines tâches humaines protègent les autres d’une substitution totale.
Ces approches ont permis des progrès significatifs en termes de macro-analyse. Elles reposent souvent :
– soit sur une granularité métier large,
– soit sur des méthodes non reproductibles ou peu évolutives (notation reposant sur des évaluations d’experts, figée dans le temps),
– soit, pour les méthodes récentes, sur des estimations par LLM, intermédiaires dont la méthodologie et les critères de décision sont peu contrôlables et par nature non transparents.
Une approche complémentaire : extraction linguistique automatisée des tâches
Notre démarche propose une alternative fondée sur deux évolutions méthodologiques :
– Descendre à l’échelle de la tâche élémentaire, en extrayant directement le couple action–objet (verbe–COD) et ses modificateurs à partir des descriptions textuelles type O*NET.
– Automatiser l’extraction linguistique, sans passer par l’intermédiation opaque d’un LLM, mais en mobilisant des outils de traitement du langage naturel (NLP) classiques et entièrement paramétrables.
Ainsi, cette approche permet :
– D’augmenter fortement la granularité d’analyse,
– De traiter des bases de tâches volumineuses,
– De garantir une transparence sur les règles d’extraction et de notation,
– D’adapter dynamiquement les pondérations en fonction de l’évolution des capacités IA.
Le NLP (Natural Language Processing) en pratique : qu’est ce que c’est ?
Le NLP permet d’automatiser l’analyse à grande échelle. On utilise un outil de traitement linguistique, dans Python par exemple (ici Stanza et spaCy), pour analyser le texte qui décrit les tâches des métiers. Le texte est décomposé en unités (ou tokens) lexicaux. Ensuite, le traitement linguistique effectué par spaCy produit un classement grammatical des différents token lexicaux (noms, pronoms, adjectifs, verbes, etc.) : c’est le POS (part-of-speech-tagging). Un label POS (tag) est attribué à chaque élément selon son usage grammatical dans la phrase étudiée.
Stanza (ou spaCy) extrait également la structure grammaticale d’une phrase : les relations entre les mots. C’est l’analyse syntaxique en dépendance (dependency parsing). On peut représenter ces dépendances par un arbre ou un graphe dirigé, exprimant donc des relations hiérarchiques entre les mots. La racine de la phrase est le plus souvent le verbe. Par exemple, dans la phrase “l’observatoire analyse les données”, données dépend de analyse : pour spaCy, le mot données sera dépendant (child) du mot analyse.
L’étape de l’analyse textuelle est cruciale : elle permet de classifier les éléments des tâches (verbe ou combinaison verbe + COD par exemple) afin de rationaliser l’évaluation de la propension d’automatisation de chaque tâche. Une fois l’analyse linguistique effectuée, on établit des règles pour classer chacune des tâches, et lui attribuer un score d’automatisation.
Prenons trois règles simples pour illustrer.
– La règle 1 pourrait consister à choisir des verbes pour chaque étape de l’IA et leur associer un score. Par exemple, avec les LLMs, on pourrait indiquer que le verbe “écrire” correspond à une automatisation à 70% mais le verbe “évaluer” à une automatisation à 50% seulement.
– La règle 2 pourrait nuancer cette approche : lorsque le verbe “écrire” est suivi du COD “budget”, on considère que l’automatisation n’est en réalité pas possible à 70% par LLM mais à 20% seulement, car cette action implique une notion de stratégie, étrangère aux LLMs.
– La règle 3 nous permettrait de nous assurer que le modificateur ne change pas totalement le contexte de la phrase : par exemple, le triplet “use, tool, statistical” renvoie à une tâche en grande partie automatisable par LLM tandis que le triplet “use, tool, wood” renvoie à une tâche physique qui n’est absolument pas automatisable par LLM.
Notre méthodologie est une version très complexe de ces principes.
Méthode en détails
🔹 Extraction linguistique : au-delà du parsing naïf
L’analyse repose sur un pipeline d’extraction automatisée des actions élémentaires, en combinant outils de traitement du langage naturel (NLP) classiques et stratégies de correction spécifiques.
1. Analyse syntaxique complète (via Stanza)
Chaque phrase de tâche est analysée pour en extraire les structures grammaticales : verbe, complément d’objet direct (COD), modificateurs, subordonnées.
2. Correction ciblée des erreurs d’analyse
Certaines descriptions de tâches, longues ou complexes, génèrent des erreurs du parsing (analyse grammaticale) effectué par Stanza. Pour les corriger, on procède par étapes :
– Reclassement des verbes ambigus (e.g., monitor, review) mal étiquetés par Stanza,
– Retraitement local via spaCy pour accélérer les corrections syntaxiques,
– Désactivation des verbes utilisés comme qualificatifs (participes adjectivaux, relatives clauses).
Par ailleurs, les participes adjectivaux et structures qui ne reflètent pas une action pertinente sont filtrés pour éviter les faux positifs. Par exemple dans la tâche “treat patients who are injured“, on ne veut pas conserver le couple (“be“, “injured“) car il ne se rapporte pas aux actions du métier considéré.
3. Enrichissement des couples verbes et COD (modifieurs, expansions, compléments)
Le couple (verbe, COD) est complété par :
– des modificateurs nominaux (e.g., customer data → modif = customer),
– des expansions sémantiques (e.g., such as reports and charts),
– des compléments syntaxiques (e.g., with software, by analyzing trends).
4. Propagation dans les structures complexes
Les objets sont propagés entre verbes coordonnés (conj), subordonnés (xcomp, acl) ou liés par dépendance syntaxique, avec garde-fous pour éviter les erreurs (exclusion de groupes nominaux suivant immédiatement un verbe, vérification des possessifs, etc.).
5. Gestion des cas limites : procédure de secours (fallback) et nettoyage
Lorsque l’analyse échoue à extraire un verbe exploitable, une procédure de secours (fallback) :
– détecte le premier nom pertinent de la phrase
– construit un triplet minimal, garantissant un résultat même en cas de parsing défaillant.
Exemple de sortie :("analyze", "data", "customer", "modifier", ("using software", "prep"))
Ce triplet signifie que la tâche contient une action analyze data, modifiée par customer et enrichie d’un complément using software.
🔹 Notation multi-scénario : une approche modulaire avec paramètres ajustables (YAML)
Chaque tâche est évaluée selon plusieurs profils d’intelligence artificielle indépendants : LLM, Agent autonome, Workflow automatisé, IA Générale, Robotique humanoïde. Pour chaque profil, un ensemble de règles spécifiques est défini dans le YAML, permettant d’ajuster dynamiquement tous les critères de notation sans modifier le code source.
Chaque tâche reçoit un score d’automatisation compris entre 0 et 1, représentant la proportion d’automatisation potentielle. Concrètement, la tâche “traduire un texte” pourrait obtenir un score de 0,8 si l’on considère que 80% du travail est automatisable mais que 20% d’intervention humaine est encore requis.
🔹 Base de la notation : typologie sémantique + enrichissements WordNet
Chaque triplet (verbe – complément d’objet direct – modifieur) reçoit un score de base en fonction :
– Du type d’action détecté (catégorie WordNet : cognition, communication, création…).
Exemple : analyze → catégorie cognitive.
– Des hyperonymes associés aux verbes (concepts plus généraux enrichissant la pondération).
Exemple : calculate → hyperonyme think, boostant le score pour les tâches cognitives.
Le système exploite WordNet (via un algorithme Lesk amélioré) pour effectuer une désambiguïsation lexicale et ajuster finement les scores selon la nature de l’action détectée.
🔹Ajustements : exclusions, boosts et pénalités
Après l’attribution du score de base, trois types d’ajustements sont possibles :
– Exclusions :
Certaines actions sont totalement exclues du système de notation normal si elles correspondent à des critères définis
* Verbes interdits (ex : sing exclu),
* Appartenance à un groupe de verbes exclus (ex : groupe manual contenant paint, assemble),
* COD désignant un humain ou une catégorie sensible (ex : patient, client).
Les exclusions sont prioritaires : si une tâche est exclue, son score est directement ramené à 0,01.
– Boosts :
Un boost augmente le score pour des éléments ou combinaisons favorables à l’automatisation :
* Verbe seul (ex : calculate boosté pour LLM),
* Groupe de verbes (ex : cognition_pure boosté pour LLM),
* Couple Verbe + COD (ex : (record, information) boosté),
* Catégorie du COD (ex : administratif boosté).
– Pénalités :
A l’inverse, une pénalité réduit le score si la tâche présente des éléments complexes ou humains :
* Verbe pénalisé (ex : recommend ou command pénalisé pour LLM),
* Groupe de verbes pénalisé (ex : negotiation pénalisé pour LLM),
* Couple Verbe + COD (ex : (perform, action) fortement pénalisé),
* Triplet Verbe + COD + Modifieur (ex : (document, file, harassment) pénalisé).
🔹 Cibles des ajustements : catégories vs éléments individuels
Les ajustements (exclusions, boosts, pénalités) peuvent s’appliquer :
– À des éléments individuels :
Verbe seul (ex : “analyze”), COD seul (ex : “data”, “patient”), Modificateur seul (ex : “sensitive”, “automated”),
– À des combinaisons spécifiques :
* Verbe + COD,
* Verbe + Modifieur,
* Verbe + COD + Modifieur.
– À des grandes catégories :
* Catégorie WordNet du verbe (ex : “cognitive”, “manuelle”),
* Catégories définies dans le YAML.
Par exemple, on peut créer une liste de verbes appelée “manuel” qui requiert une intervention physique, ou une liste de verbe + COD qui indiquent une représentation artistique.
Cette approche permet une granularité importante dans l’évaluation, sans jamais toucher au code source.
🔹 Pondération des tâches
Enfin, les tâches sont pondérées selon leur importance dans le métier, précisée dans O*NET :
– Core tasks reçoivent un poids plus élevé (ex : 5.0),
– Supplemental tasks un poids plus faible (ex : 1.0).
Ces pondérations sont utilisées pour calculer des scores d’automatisation pondérés au niveau métier.
En l’absence d’une pondération spécifique, un score par défaut est attribué (configurable dans le YAML).
Limites méthodologiques
La méthode présente cependant certaines limites :
– Limites techniques :
Même si de nombreux ajustements tentent d’en corriger les erreurs, la qualité de l’analyse syntaxique reste dépendante des performances du modèle NLP utilisé (ici Stanza principalement, et Spacy pour des cas limites). En dépit des nombreuses exceptions présentes dans le code, des classifications imparfaites demeurent pour les tâches très longues et très complexes, contenant de nombreuses conjonctions de subordination.
– Caractère prospectif des règles de notation
L’analyse demeure par essence une analyse prospective : les scores d’automatisations attribués reposent sur une certaine forme d’arbitraire ou plutôt dépendent de la capacité à anticiper plus ou moins correctement des transformations incertaines. Cette approche doit donc être considérée comme telle : une approche prospective dans un contexte de forte incertitude.
– D’un point de vue conceptuel, l’approche par tâche, si elle affine l’analyse, ne remplace pas une évaluation directe par processus de production : cette dernière, plus coûteuse, reste optimale pour anticiper les recompositions profondes du travail sous l’effet de l’IA.
En effet, l’analyse des tâches, à elle seule, ne suffit pas : l’IA, en modifiant les processus de production peut rendre des métiers obsolètes même si leurs tâches demeurent peu automatisables. Par exemple, les tâches d’un caméraman – cadrer, filmer, ajuster les prises – restent difficilement automatisables. Et pourtant, avec la génération automatique de films par IA, la demande de captation humaine elle-même pourrait s’effondrer.
Références
– David H. Autor, Frank Levy, Richard J. Murnane, The Skill Content of Recent Technological Change: An Empirical Exploration, The Quarterly Journal of Economics, Volume 118, Issue 4, November 2003, Pages 1279–1333
– Berg, J., Gmyrek, P., Kamiński, K., Konopczyński, F., Ładna, A., Nafradi, B., Rosłaniec, K., Troszyński, M. Generative AI and jobs: A refined global index of occupational exposure, ILO Working Paper, No. 140, ISBN 978-92-2-042185-7, International Labour Organization (ILO), Geneva.
– Brynjolfsson, E., Mitchell, T., & Rock, D. (2018). What can machines learn, and what does it mean for occupations and the economy? AEA Papers and Proceedings, 108, 43-47.
– Felten, E., Raj, M., & Seamans, R. (2021). Occupational, industry, and geographic exposure to artificial intelligence: A novel dataset and its potential uses. Strategic Management Journal, 42(12), 2195–2217.
– International Monetary Fund. (2024). Generative Artificial Intelligence and the Future of Work. IMF Staff Discussion Note SDN/2024/001. Washington, DC: International Monetary Fund.
– Webb, M. (2019). The impact of artificial intelligence on the labor market.
– Eloundou, T., Manning, S., Mishkin, P., & Rock, D. (2023). GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models. arXiv:2303.10130.
– Loaiza, Isabella and Rigobon, Roberto, The EPOCH of AI: Human-Machine Complementarities at Work (November 21, 2024). MIT Sloan Research Paper No. 7236-24, Available at SSRN: https://ssrn.com/abstract=5028371 or http://dx.doi.org/10.2139/ssrn.5028371
– Noy, S., & Zhang, W. (2023). Experimental evidence on the productivity effects of generative artificial intelligence. Science, 2023, 381(6654), p.187-192.